Boost
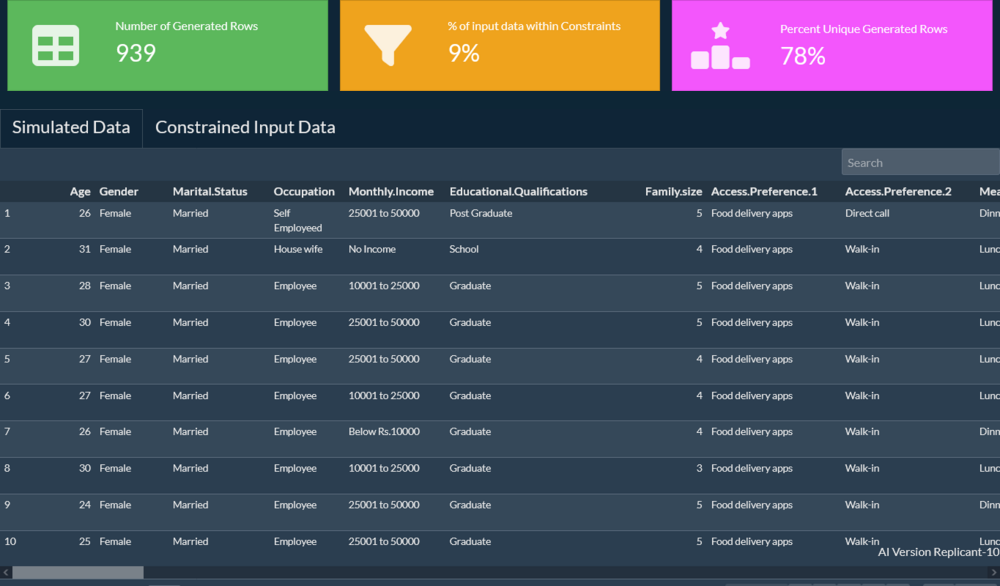
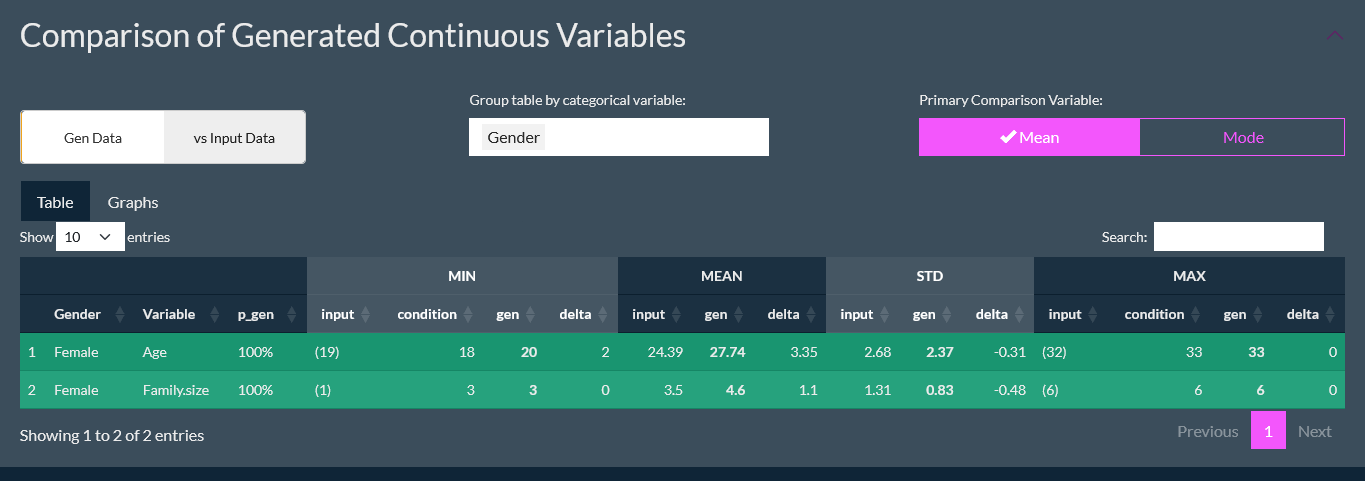
Expand an under-sampled population or cohort in your existing research. Synthesized rows behave the way your respondent population behaves.
Stabilize
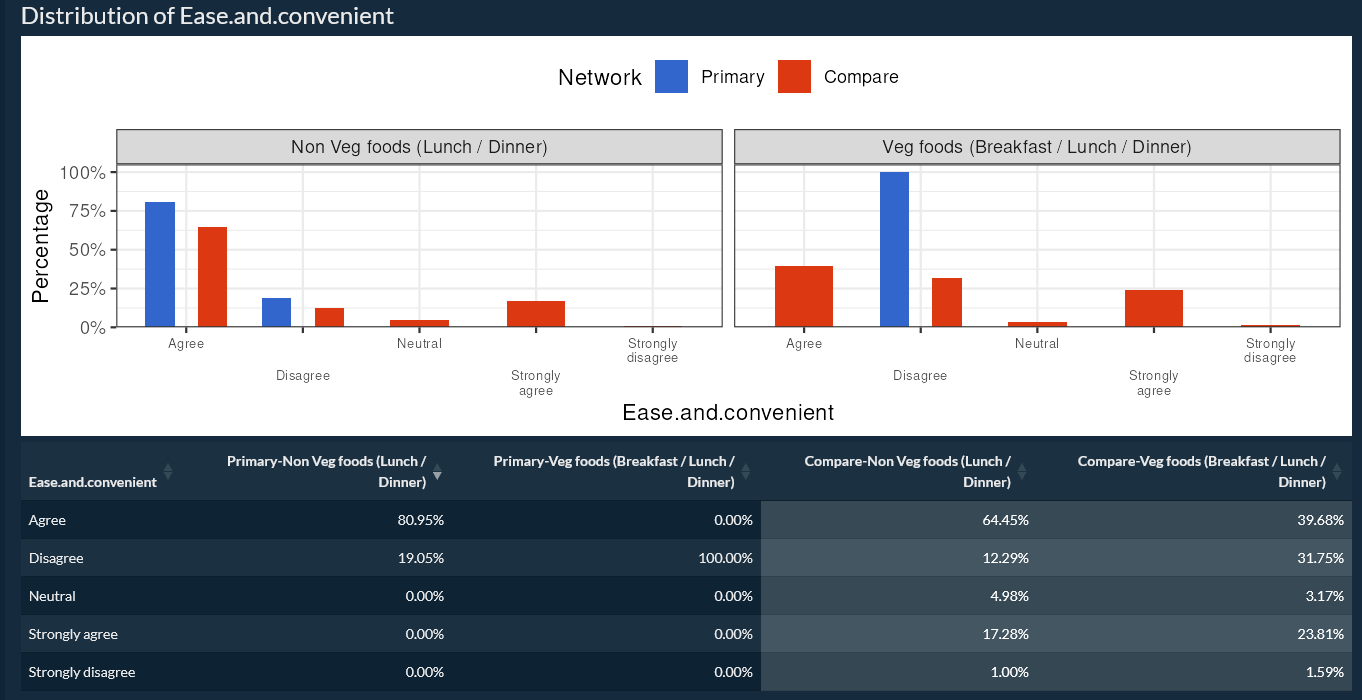
Reduce volatility in tracker cuts wave-over-wave. Borrows strength from prior waves while preserving wave-level signal.
Scenario
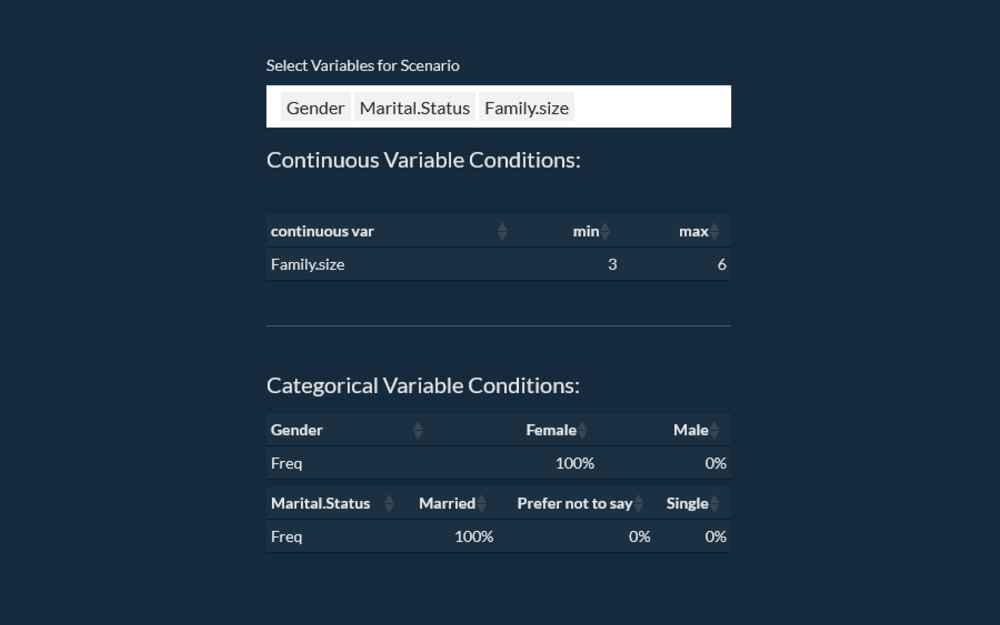
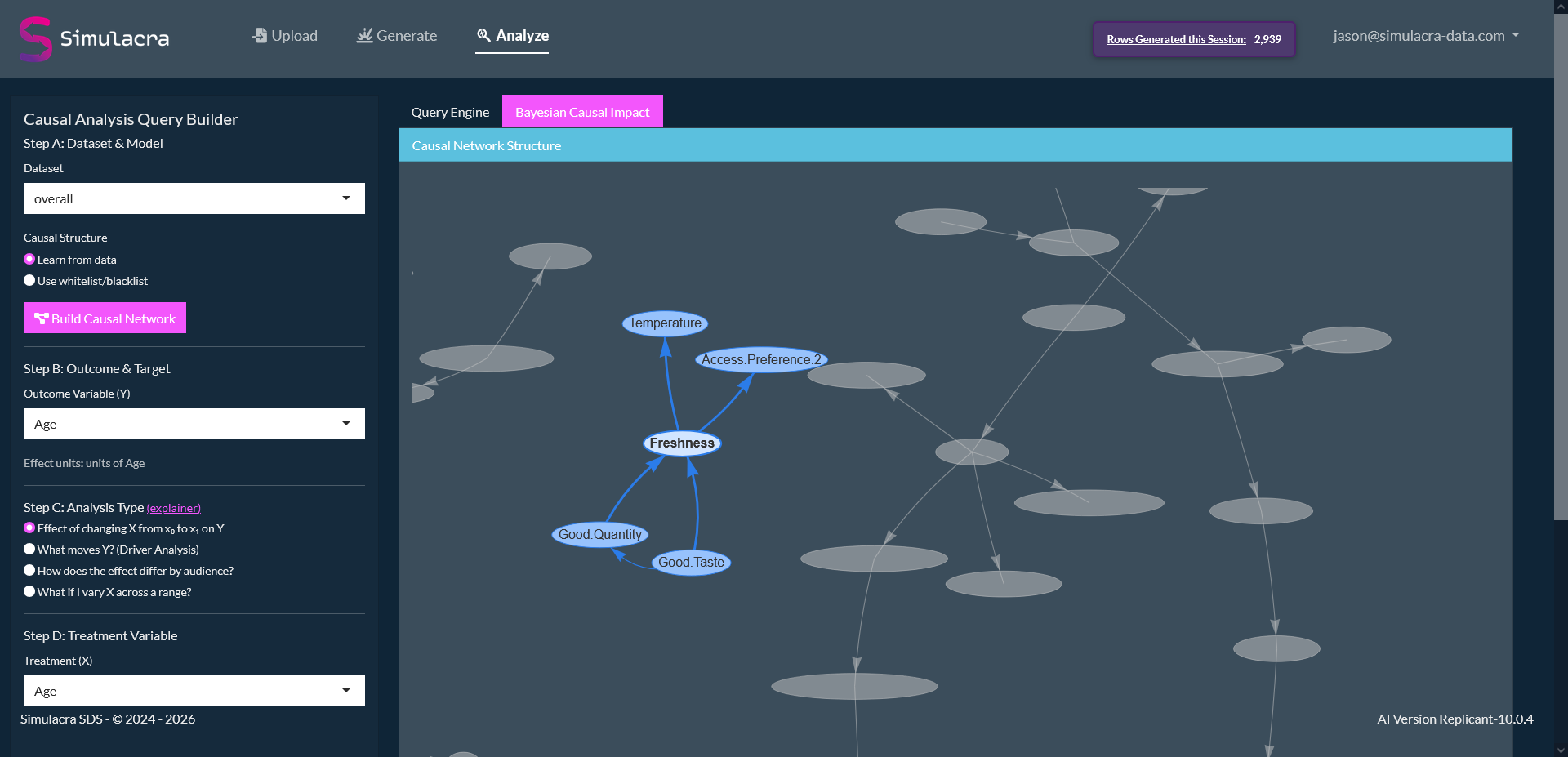
Run do(X) interventions and audience rebalancing, then inspect how downstream variables shift together. Predict the way your respondent population would actually respond.
Schema inspector
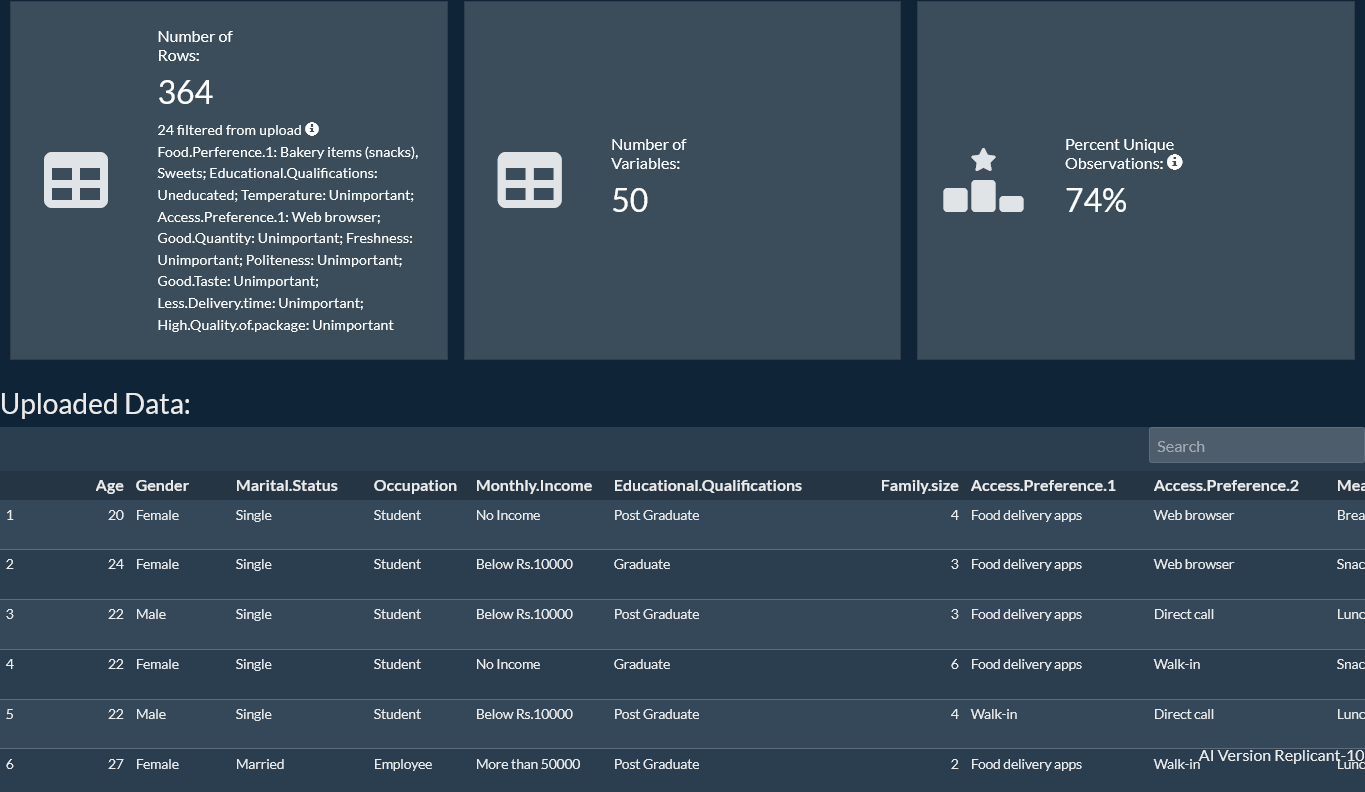
View the cleaned schema the engine actually trained on, after our automated cleaning: column names, levels, low-signal drops.
Govern
Synthetic-row labels on every export, scenario assumptions captured in the methodology appendix, project-level access controls.
Export
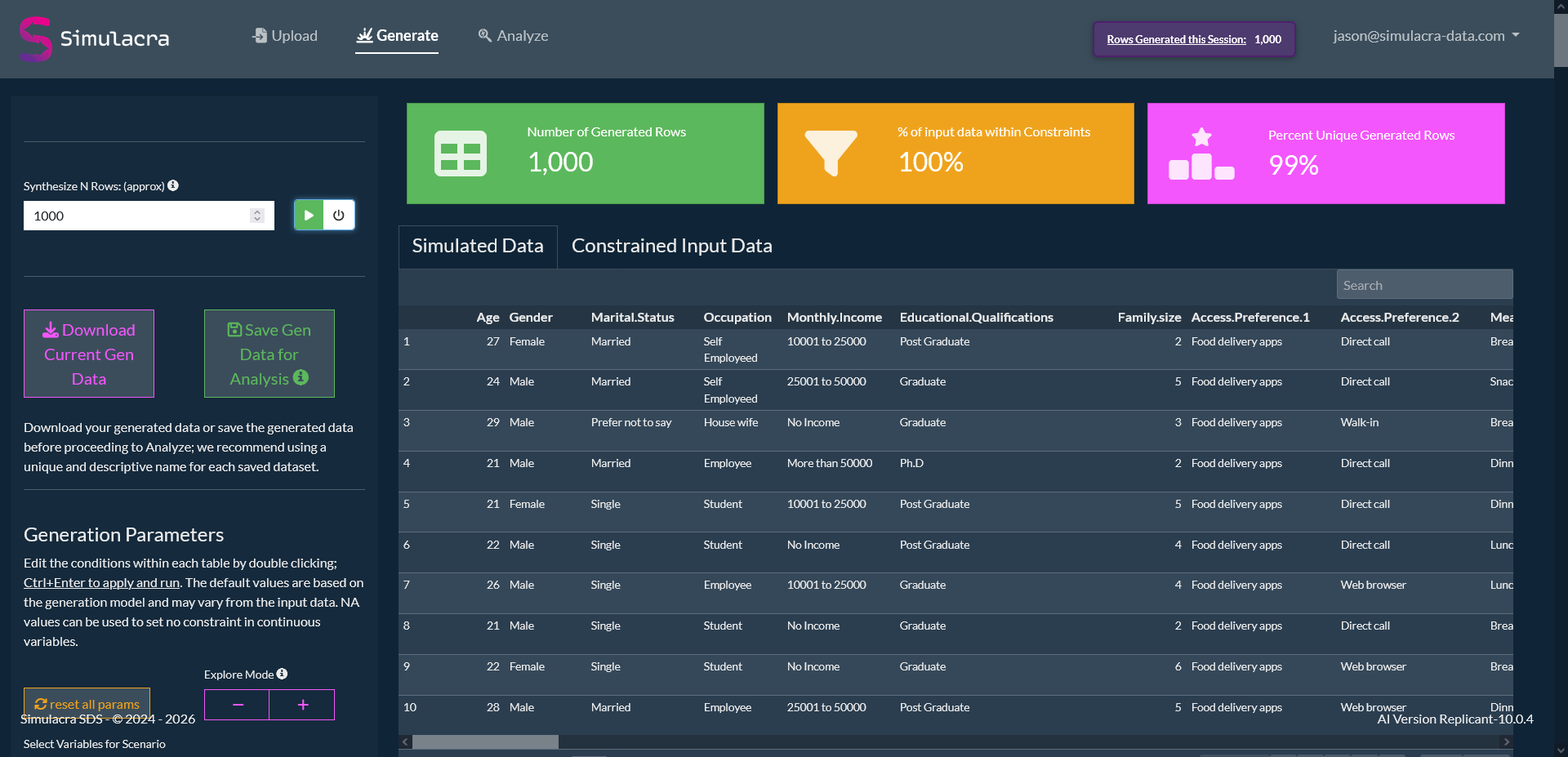
CSV, Parquet, SPSS, R, Python, Tableau, Power BI. Methodology appendix attached on every export.
ACE / CATE
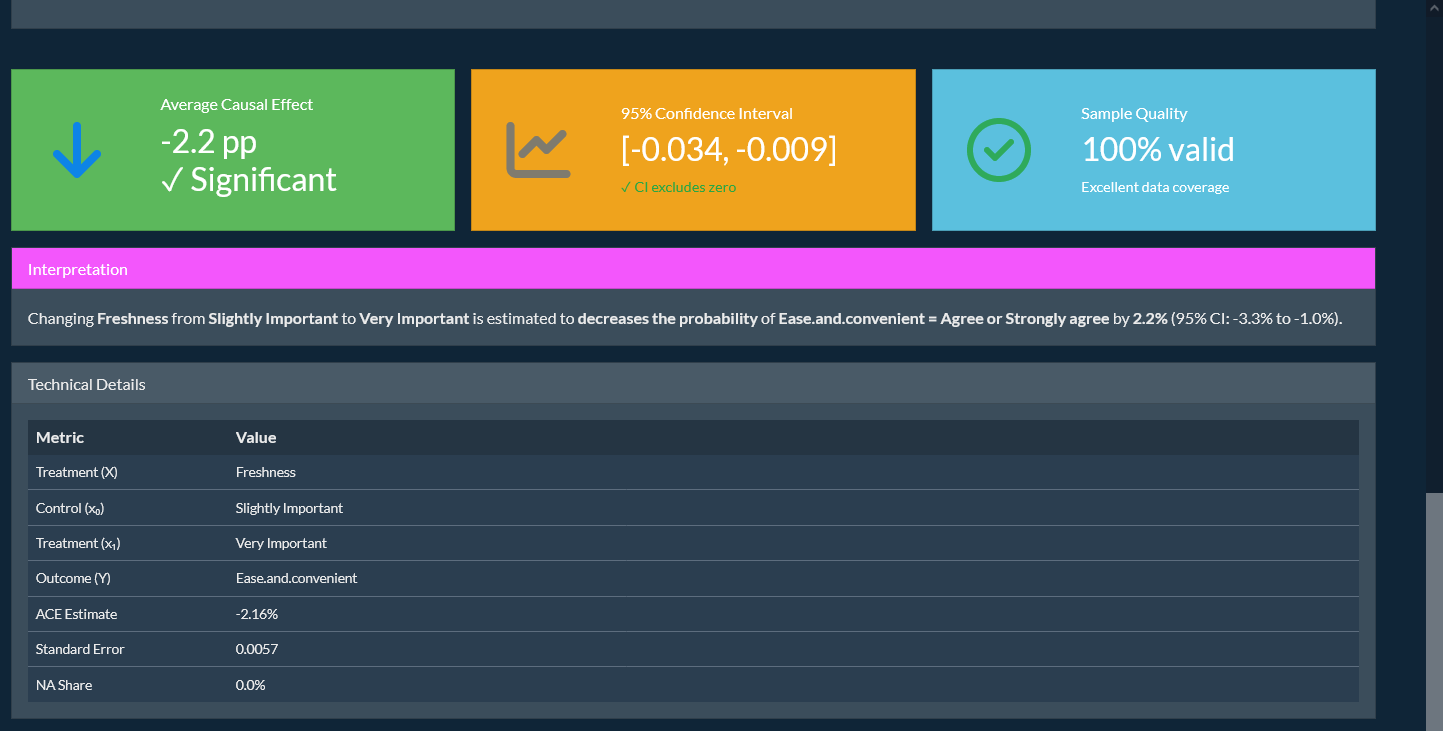
Predict causal effects on generated populations and outcome scenarios, plus segment-level heterogeneous effects and automated reporting. Read more.
Validate
Holdout backtests, distribution overlap checks, novelty audit, infeasibility reports. Run on any customer dataset, anytime, by the Simulacra team.
Data security
Each project runs in an isolated single-tenant container. Customer data is trained zero-shot, processed in memory, and never combined with another customer's data.